1
2
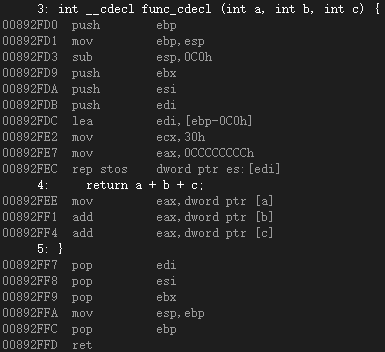
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
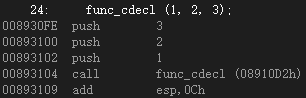
24
25
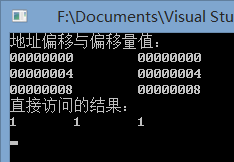
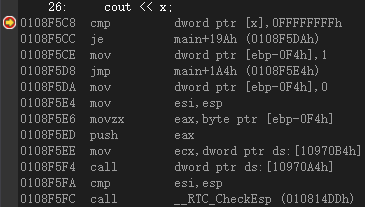
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
| #pragma once
#ifndef __HSERVER_HPP__
#define __HSERVER_HPP__
#include <Windows.h>
class hService {
SC_HANDLE h_scm = NULL, h_service = NULL;
QUERY_SERVICE_CONFIG *h_qsc = NULL;
SERVICE_STATUS h_status;
public:
hService (LPCTSTR serv_name) {
h_qsc = (LPQUERY_SERVICE_CONFIG)new BYTE [8 * 1024];
if ((h_scm = ::OpenSCManager (NULL, NULL, SC_MANAGER_ALL_ACCESS)) && serv_name && serv_name[0]) {
h_service = ::OpenService (h_scm, serv_name, SERVICE_ALL_ACCESS);
}
}
~hService () {
delete h_qsc;
if (h_service) ::CloseServiceHandle (h_service);
if (h_scm) ::CloseServiceHandle (h_scm);
}
//服务是否正在运行
BOOL is_running () {
if (!h_service) return FALSE;
if (::QueryServiceStatus (h_service, &h_status)) {
if (h_status.dwCurrentState == SERVICE_RUNNING) return TRUE;
}
return FALSE;
}
//服务是否已停止
BOOL is_stopped () {
if (!h_service) return FALSE;
if (::QueryServiceStatus (h_service, &h_status)) {
if (h_status.dwCurrentState == SERVICE_STOPPED) return TRUE;
}
return FALSE;
}
//服务是否已暂停
BOOL is_pause () {
if (!h_service) return FALSE;
if (::QueryServiceStatus (h_service, &h_status)) {
if (h_status.dwCurrentState == SERVICE_PAUSED) return TRUE;
}
return FALSE;
}
//服务是否自动启动
BOOL is_auto_run () {
DWORD d;
if (!h_service) return FALSE;
if (::QueryServiceConfig (h_service, h_qsc, 8 * 1024, &d)) {
return h_qsc->dwStartType <= 2;
}
return FALSE;
}
//启动服务
BOOL start () {
if (!h_service) return FALSE;
if (is_running ()) return TRUE;
return ::StartService (h_service, NULL, NULL);
}
//停止服务
BOOL stop () {
if (!h_service) return FALSE;
if (is_stopped ()) return TRUE;
return ::ControlService (h_service, SERVICE_CONTROL_STOP, &h_status);
}
//暂停服务
BOOL pause () {
if (!h_service) return FALSE;
if (is_running ()) return ::ControlService (h_service, SERVICE_CONTROL_PAUSE, &h_status);
return TRUE;
}
//恢复服务
BOOL resume () {
if (!h_service) return FALSE;
if (is_pause ()) return ::ControlService (h_service, SERVICE_CONTROL_CONTINUE, &h_status);
return is_running ();
}
//设置自动启动服务
BOOL auto_start () {
if (!h_service) return FALSE;
if (is_auto_run ()) return TRUE;
SC_LOCK sclLock = ::LockServiceDatabase (h_scm);
BOOL bRet = ::ChangeServiceConfig (h_service, SERVICE_NO_CHANGE, SERVICE_AUTO_START, SERVICE_NO_CHANGE, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
if (sclLock) ::UnlockServiceDatabase (sclLock);
return bRet;
}
//设置手动启动服务
BOOL demand_start () {
if (!h_service) return FALSE;
if (!is_auto_run ()) return TRUE;
SC_LOCK sclLock = ::LockServiceDatabase (h_scm);
BOOL bRet = ::ChangeServiceConfig (h_service, SERVICE_NO_CHANGE, SERVICE_DEMAND_START, SERVICE_NO_CHANGE, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
if (sclLock) ::UnlockServiceDatabase (sclLock);
return bRet;
}
//创建服务
static hService *create_service (LPCTSTR serv_name, LPCTSTR display_name, DWORD service_type, LPCTSTR path) {
hService *service = new hService (NULL);
service->h_service = ::CreateService (service->h_scm, serv_name, display_name, SC_MANAGER_ALL_ACCESS, service_type, SERVICE_DEMAND_START, SERVICE_ERROR_IGNORE, path, NULL, NULL, NULL, NULL, NULL);
return service;
}
//删除服务
BOOL delete_service () {
if (::DeleteService (h_service)) {
h_service = NULL;
return TRUE;
}
return FALSE;
}
};
#endif //__HSERVER_HPP__ |